前言
网络爬虫的防封措施中最主要的就是更换代理ip,但是个人为了学习爬虫而购买代理ip划不来,所以我们应该从免费的ip代理网站获取这些免费ip.这就是文章由来.
设计
- 通过爬虫把免费代理ip爬取到本地
- 使用subproccess模块调用系统的ping命令过滤掉无效ip
网页分析
我们以西刺网站为例,可以发现网站免费代理ip并没有通过js动态加载,所以爬取并不复杂,我这里就不分析了. 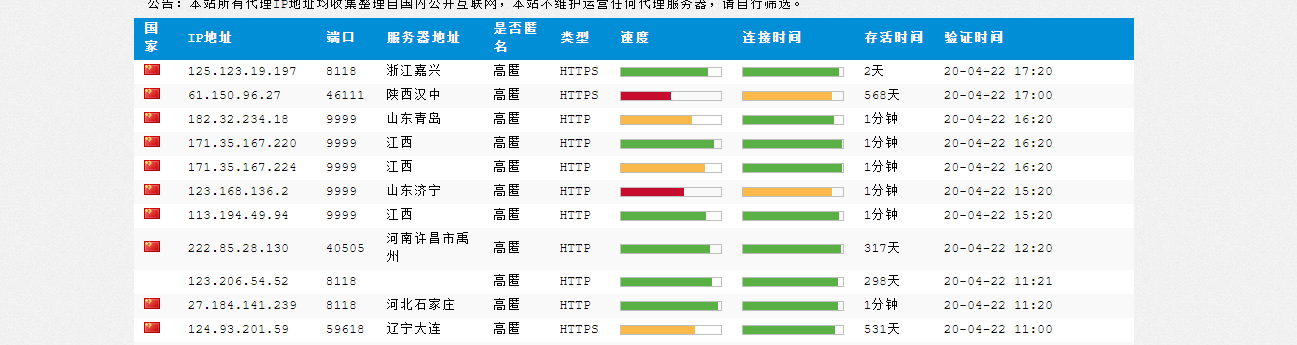
具体实现
封装提取规则函数,我们只需要协议,ip,端口
def xiciParser(html): proxyList=[] doc=pq(html) itemsIter=doc('#ip_list tr').items() for tr in itemsIter: ip=tr('td:nth-child(2)').text() port=tr('td:nth-child(3)').text() protocol=tr('td:nth-child(6)').text() proxyList.append((protocol,ip,port)) return proxyList[1:]
使用上面的函数,实现爬取西刺的代理ip,返回一个列表
def getProxyList(page): #席次代理的ip页面规则是http://www.xicidaili.com/nn/页码 xici_url='http://www.xicidaili.com/nn/%s' %(page) headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36' } s=requests.session() res=s.get(url=xici_url,headers=headers) html='' if res.status_code==200: res.encoding='utf-8' html=res.text return xiciParser(html)
重头戏,我们封装一个检测ip有效性的方法,使用的是subproccess模块调用系统的ping命令
def checkIP(ip): # -n 3代表发送三次请求,-w 3代表最长等待时间3秒 cmd ="ping -n 3 -w 3 %s" %(ip) #stdout=sp.PIPE表示,执行后的输出结果赋值给stdout变量,我们通过分析stdout就可以知道请求的结果 p=sp.Popen(cmd,stdout=sp.PIPE,shell=True) #cmd命令默认输出字符编码是'gbk' out=p.stdout.read().decode('gbk') #开始分析结果 #匹配丢包数的正则 lostPacketRe=re.compile(u'丢失 = (\d+)') waitTimeRe=re.compile(u'平均 = (\d+)ms') lostPacket=lostPacketRe.findall(out) #如果匹配规则lostPacket失效,那么代表ip根本不存在,认为三次都丢包 if len(lostPacket) == 0: lose=3 else: lose = int(lostPacket[0]) #如果丢包超过两个就默认延迟1000毫秒 if lose >2: return 1000 #如果丢包数小于等于2,就判断延迟时间 else: waitTime=waitTimeRe.findall(out) #如果找不到延迟的时间,也是找不到ip,所以返回延迟1000 if len(waitTime)==0: return 1000 else: return int(waitTime[0])
这张图就是ping命令的返回结果,我们的checkIP函数就是分析它
爬取到代理ip的列表后,通过检测ip有效性的方法过滤掉无效ip
#对代理ip列表进行测试,延迟200毫秒以内的都保留,最终返回有效ip列表 #就算是有效ip,但是也要注意,这种烂大街的ip,可能会被一些网站封锁 def proxyListfilter(proxyList): length=len(proxyList[0:20]) i=0 for proxy in proxyList[0:20]: protocol,ip,port=proxy waitTime=checkIP(ip) if waitTime>200: proxyList.remove(proxy) i+=1 print(ip+'是无效的ip,无效个数 '+str(i)+' / '+str(length)) return proxyList
完整实例代码在我的github上面下载
结束语
我们这只是个简单demo,但有了思路,大家就能制作出自己的代理ip池,让大家的爬取更加安全.